精品大數(shù)據(jù)項目 基于詩詞語義特征分析的古代社會經(jīng)濟水平變化研究及其計算機系統(tǒng)服務
項目概述
本項目是一項融合了文學、歷史學、經(jīng)濟學與計算機科學的交叉學科研究。它旨在通過大數(shù)據(jù)技術(shù),特別是自然語言處理(NLP)與機器學習方法,對海量古代詩詞文本進行深度挖掘,從中提取能夠反映社會經(jīng)濟狀況的語義特征,進而量化分析并可視化展示中國古代社會經(jīng)濟水平的長期變化趨勢。本項目不僅是一項前沿的學術(shù)探索,更提供了一套完整的、可復用的計算機系統(tǒng)服務解決方案。
核心技術(shù)與方法
- 數(shù)據(jù)采集與預處理:
- 語料庫構(gòu)建:系統(tǒng)性地收集從先秦至清代的詩詞全集,建立大規(guī)模、跨朝代的結(jié)構(gòu)化文本數(shù)據(jù)庫。
- 數(shù)據(jù)清洗:利用Python(如
Jieba、HanLP等工具)進行自動分詞、詞性標注、去除停用詞、古籍繁體字轉(zhuǎn)簡體等標準化處理。
- 語義特征工程:
- 主題建模:采用LDA(Latent Dirichlet Allocation)等主題模型,從詩詞中自動識別出如“農(nóng)耕”、“商貿(mào)”、“戰(zhàn)爭”、“宴飲”、“民生疾苦”、“宮廷奢華”等潛在主題,作為社會經(jīng)濟活動的代理變量。
- 情感與價值詞分析:構(gòu)建經(jīng)濟相關(guān)的情感詞典與關(guān)鍵詞庫(如“米貴”、“豐收”、“市井”、“賦稅”、“絲綢”、“舟車”等),統(tǒng)計其詞頻、共現(xiàn)網(wǎng)絡及情感傾向隨時間的演變。
- 嵌入表示學習:使用Word2Vec、BERT等預訓練模型或訓練特定歷史語料的詞向量,從語義層面捕捉詞語的上下文關(guān)聯(lián),量化分析經(jīng)濟相關(guān)概念的語義場變化。
- 經(jīng)濟水平量化與建模:
- 指標構(gòu)建:將提取的語義特征(如主題強度、關(guān)鍵詞頻率、積極經(jīng)濟情感比例等)聚合為年度或朝代級別的綜合指數(shù),嘗試構(gòu)建“詩詞反映的經(jīng)濟景氣指數(shù)”。
- 相關(guān)性驗證:將量化結(jié)果與歷史學界公認的經(jīng)濟史料記載(如人口數(shù)據(jù)、糧價記錄、稅收數(shù)額等)進行對比分析,驗證模型的有效性與解釋力。
- 趨勢分析與周期探測:運用時間序列分析、回歸模型等方法,探測社會經(jīng)濟變化的長期趨勢、波動周期及可能的轉(zhuǎn)折點。
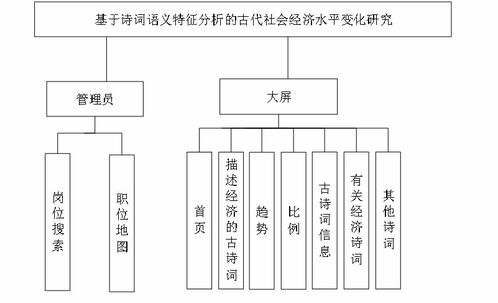
- 可視化與系統(tǒng)服務:
- 動態(tài)交互可視化:利用
ECharts、Plotly等庫,開發(fā)交互式圖表,展示經(jīng)濟指數(shù)的時間折線、主題熱力圖、關(guān)鍵詞云圖、地理空間分布圖等。
- Web系統(tǒng)服務:基于
Flask或Django框架,搭建B/S架構(gòu)的計算機系統(tǒng)服務平臺。該平臺提供:
- 數(shù)據(jù)查詢接口:按朝代、作者、地域、經(jīng)濟關(guān)鍵詞等多維度檢索相關(guān)詩詞及分析結(jié)果。
- 分析報告生成:用戶可選擇時間段或朝代,系統(tǒng)自動生成社會經(jīng)濟變化分析簡報與可視化圖表。
- 模型API服務:為其他研究提供語義特征提取、經(jīng)濟指數(shù)計算的標準化API接口,促進學術(shù)資源共享。
創(chuàng)新點與價值
- 方法論創(chuàng)新:開辟了利用非結(jié)構(gòu)化文學文本進行社會經(jīng)濟史量化研究的新路徑,為“數(shù)字人文”提供了典型范例。
- 視角新穎:從民眾情感與日常書寫(詩詞)的微觀視角,補充了以正史、政書為主的宏觀經(jīng)濟史研究,可能揭示更細膩的社會經(jīng)濟脈動。
- 技術(shù)驅(qū)動:全面應用當代大數(shù)據(jù)與AI技術(shù)處理傳統(tǒng)人文學科問題,體現(xiàn)了學科融合的強大潛力。
- 服務化輸出:項目成果不止于論文,更以可操作的計算機系統(tǒng)服務形式交付,具備良好的擴展性、可復用性及實用價值,可供歷史、文學研究者及教育機構(gòu)直接使用。
應用前景
本項目構(gòu)建的技術(shù)框架與系統(tǒng)服務,可進一步拓展至其他文學體裁(如小說、筆記)、其他歷史維度(如氣候變化、社會觀念變遷)的分析,為文化遺產(chǎn)的數(shù)字化解讀與智能信息服務平臺建設奠定堅實基礎。它不僅是學術(shù)研究的利器,也是文化科技融合創(chuàng)新的有益實踐。
如若轉(zhuǎn)載,請注明出處:http://www.gbw999.cn/product/30.html
更新時間:2026-05-24 23:43:13